Demystifying the AI Jargon Minefield
In this article I aim trying to demystify some of the commonly used jargon in DS/AI and attempt make it more understandable.
Sunil Singh
5/2/202310 min read


In the past 6 to 8 years, Data Science (DS)/Artificial Intelligence (AI) has transitioned from the research labs to the mainstream as a feature of frequently used apps. After the release of ChatGPT, there has been so much buzz and excitement that even the average person is aware of what ChatGPT is. But still, most of us find the jargon and terminology used in daily news and literature such as Data Science, Artificial Intelligence, Machine Learning, Deep Learning, Computer Vision, Natural Language Processing, etc. to be very perplexing. Based on my understanding, in this article I aim to demystify some of the commonly used jargon in DS/AI and attempt to make it more understandable.
The Holy Grail : Data
Why did the data scientist break up with her boyfriend?
"Because he had too many null values and not enough data! 😊"
But first, let’s briefly talk about data, the mother of all sins.
The Latin word datum, which means something given, is the source of the word data. It first appeared in English in the middle of the seventeenth century, referring to written data. It is important to remember that the definition and application of data can differ between various disciplines, including science, mathematics, and the social sciences.
In the early days of computing, data was primarily stored in physical formats such as punch cards and magnetic tape. But with the advent of digital storage and the internet, data has become more easily accessible and can be analyzed on a much larger scale. This has led to new fields such as data science and analytics, which use advanced algorithms to derive insights from vast amounts of data.
Information that can be processed by a computer, such as text, images, videos, and more, is now referred to as data. A greater need for data management and privacy regulations has arisen as a result of the growth in data collection and storage. In addition, a variety of industries, including finance, healthcare, and marketing, are using data more frequently in decision-making. The definition and use of data will develop even further as technology progresses, influencing how we perceive the world.
Early forms of data collection, such as the census, tax records, and even cave paintings, laid the foundation for modern data analysis methods, leading to new discoveries and advancements in a variety of fields.
How much data do we have?
Why did the data center break up with the cloud?
“Because the cloud had too much storage and was making the data center feel inadequate. Size does matter after all! 😁”
A study by IBM estimates that 2.5 quintillion bytes of data are produced daily. One quintillion is equal to one billion gigabytes, to put this into perspective.
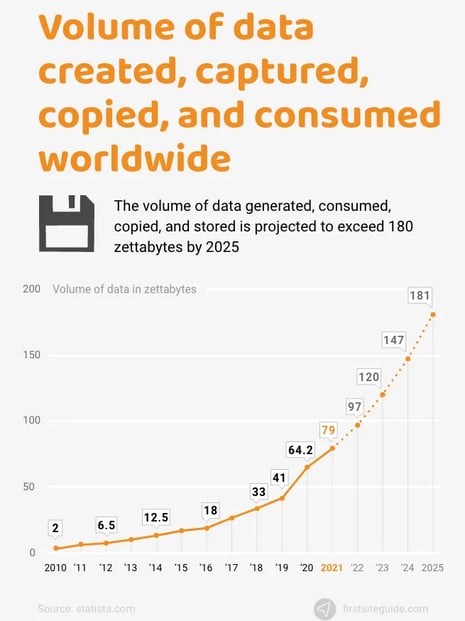
IDC predicts that by 2025, the amount of data that has been generated, collected, and replicated globally will total 175 zettabytes. For comparison, one zettabyte is equal to one trillion gigabytes.
An enormous amount of data will be produced by connected devices by 2025, when it is predicted that the average person will use them nearly 4,800 times per day.
By 2025, 10.3 zettabytes of data generated by Internet of Things (IoT) devices are anticipated to have increased to 79.4 zettabytes.
The biggest tech companies in the world, like Google, Facebook, and Amazon, produce a ton of data. While Facebook had more than 2.8 billion monthly active users in 2020, Google processed more than 3.5 billion searches daily.
Also producing enormous amounts of data is the healthcare sector. The amount of healthcare data, which includes information from sources like wearables, genomics, and electronic medical records, is predicted to increase by 36% annually through 2025, according to a Deloitte report.
The use of video is another factor in the expansion of data. According to predictions, video content will make up 80% of all internet traffic by 2025.
The need for new technologies and techniques to effectively store, manage, and analyze data is increasing as it continues to grow in volume. Big data analytics, artificial intelligence, and machine learning have all been made possible as a result, and they are now helping businesses make sense of the enormous amounts of data they are collecting.
Image Source: statista.com / firstsiteguide.com
Write your text here...
Image Source: Christian Dorn on Pixabay
And if someone is still unsure about the value of data, keep in mind that ignorance is bliss-until a business fails miserably 😇
Data is crucial because it helps businesses, people, and machines innovate, make better decisions, get new insights, increase efficiency, and automate procedures.
Assists in decision-making: Instead of relying on intuition or gut sentiments, data enables organizations to make deft choices based on real insights. Companies can make more informed decisions by analyzing data to find trends, patterns, and potential issues.
Offers insights: Data analysis can reveal information about consumer behavior, tastes, and requirements. This knowledge can assist businesses in improving product development, marketing initiatives, and consumer experiences.
Promotes innovation: Data is frequently used to find opportunities for growth or problem-solving. Innovation and the development of fresh goods, services, or procedures may result from this.
Increases effectiveness: Data may be used to streamline operations, cut expenses, and boost output. Organizations can spot inefficiencies and areas for improvement by studying data.
Facilitates automation: Machines and algorithms can learn from and adjust to new situations with the use of data, enabling automation. Operations may become more effective and efficient as a result.
Data may sometimes reveal wholly unexpected patterns that are difficult to accept. For instance, in 2011, Randall Munroe, a former NASA astronaut who now works as a web cartoonist, asserted that “if you take any article, click on the first link in the article text, not in parentheses or italics, and then repeat, you will eventually end up at “Philosophy.” This seems absurd at first glance. However, research has shown that this is actually the case. Refer to the graph below; the 95% of starting points that eventually lead to philosophy are represented by the black dots. This phenomenon is known as wiki-loops.


A Mystical Web of Dreaded Jargons
My girlfriend broke up with me because of my “lack of vocabulary”…
What’s that even supposed to mean? 🤔
Today’s buzzwords include data science, machine learning, artificial intelligence (AI), and deep learning. These terms are frequently interchanged and constantly in use. Although the data unites them all and ties them together, there are still significant differences between them.
We attempt to comprehend them one at a time, i.e., moving from outer circles into inner circles. The outer circle represents the broadest category, and the inner circles represent more specific subcategories. This approach helps us gain a better understanding of the nuances.
Data science
Data science is 20% preparing data, 80% complaining about preparing data. 😂
Data science is a multidisciplinary field that combines elements of statistics, computer science, and domain-specific-knowledge. A formal definition of data science would be `data science involves the use of statistical and computational methods to extract insights from data.
It’s much easier to comprehend the above definition…
If we think of “data science” as a very broad term that includes many different disciplines, capabilities, and methodologies
If we consider its primary objective, which is to draw insights from both structured and unstructured data to promote reasoned-decision-making, the important thing to remember is that data science does not require or restrict the use of computers or other machines to produce insights; descriptive, predictive, and prescriptive analysis can all be completed with just a pen and paper calculator; however, this may not be the most practical approach for large datasets.
Image Source: Author
The details of the experiment can be found in this article
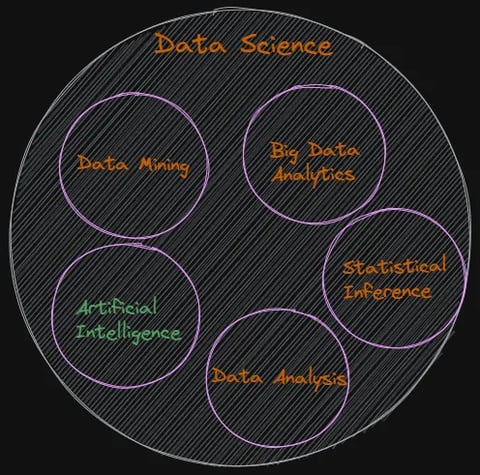
Image Source: Author
The following list contains some of the sub-disciplines of data science. In reality, these disciplines are intertwined, and there is no clear divide between them, but for the purpose of high-level understanding, I have attempted to describe them separately…
Data Mining: Data mining is used to uncover insights from large and complex datasets that may be unstructured or contain hidden patterns. Data mining is also more focused on the discovery of novel insights and patterns. Common tools include Teradata, IBM SPSS, Oracle Data Mining, RapidMiner, etc.
Data Analysis: Data analysis is the process of examining and understanding structured data using tools such as spreadsheets, SQL databases, statistical software, business intelligence tools, Python, and R.
Big Data Analytics: Big data analytics involves processing and analyzing massive volumes of data beyond the capabilities of traditional data analysis tools and methods. Common tools include Hadoop, Spark, business intelligence tools, and NoSQL databases.
Statistical Inference: Statistical inference refers to the process of drawing conclusions or making predictions about a population based on a sample of data from that population. It is an essential tool for making informed decisions and drawing valid conclusions based on empirical evidence, e.g., clinical trials, opinion polls, quality control, and environmental monitoring.
Artificial Intelligence: An umbrella discipline; we discuss this in detail in the next section.
Artificial Intelligence (AI)
It just occurred to me that the opposite of Artificial Intelligence is … “Real Stupid” 😎
The goal of artificial intelligence (AI), which is considered a branch of computer science, is to give machines the ability to perform complex tasks that are comparable to those performed by humans, including problem-solving, perception, emotion recognition and expression, and decision-making. Early attempts to use artificial intelligence (AI) in expert systems computer programs that mimic the judgement of human experts-were made in the 1970s. Expert systems are created to reason through knowledge bases that are primarily represented as if-then-else rules rather than through traditional procedural code. For instance, a robot with intelligent design and programming could do housework like sweeping, cleaning, gathering used dishes, and taking out the trash. One of the most widely used programming languages for creating expert systems was Prolog . Check out this simplified example of an expert system making use of Prolog.
Image Source: Jamie Green, Northwestern University
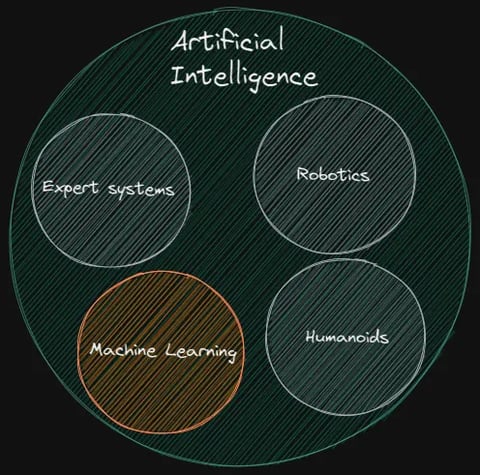
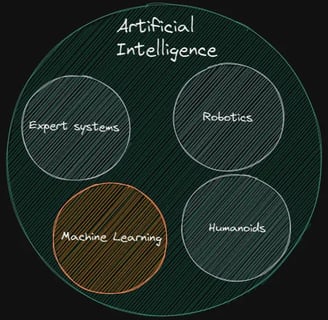
Image Source: Author
General AI, also known as artificial general intelligence (AGI), is the hypothetical ability of an AI system to perform any intellectual task that a human being can do. It is sometimes referred to as strong AI or full AI and it aims to create a machine that is capable of learning and adapting to new situations in the same way that humans do. This would require a system that is able to process and analyze data but is also able to reason about it, learn from it, and apply that learning to new situations.
Despite the fact that general AI has come a long way, it is still largely an abstract concept, and many experts believe that even if it is even possible, it will be a very long time before it is realized.
Consequently, we do not need to be concerned about machines soon taking control of our world. But let’s face it, humans are already doing a fantastic job of destroying the world, and we do not need AGI to be realized in order for that to happen. 😁
Refer to this excellent article on AGI if you are interested in more details.
Machine learning
What does a Machine Learning Specialist and a Fashion Designer have in common?
“They both specialize in curve-fitting. 😝”
A branch of artificial intelligence is machine learning. By learning from data without being explicitly programmed, it enables computer systems to automatically enhance their performance on a particular task. A machine learning model learns from data, just like people do, through practice and experience. A person’s knowledge generally advances with experience and practice. Similar to this, the model gets better and better the longer it is trained on data. For instance, if we wanted to teach a computer to recognize images of dogs, we would show it a ton of those images. The computer would then attempt to learn what characteristics, such as fur, four legs, and a tail, define a dog as a dog. The computer can then identify whether a new image is of a dog or not by looking for those characteristics when we present it to it.
There are various classifications of machine learning that one can come across in publications and literature:
By type of data and training method:
Supervised Learning: When a model is trained using labeled data, each data point is labeled with the desired outcome, which is known as supervised learning. Based on the patterns it has identified from the labeled data, the model learns to accurately predict the results for new data.
Unsupervised learning: It is the process of teaching a model to recognize patterns and data structures without being explicitly told what to look for. It involves training the model with unlabeled data.
Reinforcement Learning: Training a model to make decisions based on feedback from the environment is the process of reinforcement learning. By winning a game or finishing a task, for example, the model learns to act in a way that maximizes a reward signal.
By levels (depth) layers used by the model:
Shallow learning: A subset of machine learning techniques that relies on simpler models and is therefore less computationally intensive is referred to as shallow learning, also known as traditional or classical machine learning. When machine learning was in its infancy, these algorithms were frequently applied to solve well-defined problems involving structured data, where the connections between inputs and outputs are obvious and simple to comprehend. They remain the best option for a solution even today if a problem is appropriate for shallow learning. Since explaining how a model makes decisions is one of the main requirements made by businesses where models are expected to be used, they continue to be popular primarily because they use less compute power and, more importantly, because they are relatively easy to understand. XGBoost and Random Forest are two well-known examples of tree-based algorithms, along with support vector machines, logistic regression, K nearest neighbor and linear regression.
Deep Learning: Deep learning (DL), as the name suggests, uses multiple layers of computation (there could be 100s of layers deep) and is significantly more computationally intensive than shallow learning. Deep learning’s main benefit is its capacity to learn from complex and unstructured data, including text, audio, video and image. Deep learning algorithms can automatically learn the features and patterns from the raw data, in contrast to traditional machine learning algorithms, which depend on manually created features and rules to represent the data. Overall, deep learning has transformed many disciplines, including computer vision, natural language processing, and speech recognition. They are the driving force behind the exciting new tech such as self-driving cars and large-language-models (LLMs). DL has also made it possible to create intelligent systems that are capable of carrying out tasks that were previously thought to be beyond the capabilities of computers. The decision-making process of a deep-learning model is opaque and extremely challenging to understand, which is one of its main disadvantages in addition to the demand for significant computing power. The term "neural networks" is also used to describe deep learning models. Constitutional Neural Networks (CNN), Long-Short Term Memory (LSTM), Generative Adversarial Network (GAN) and Transformers are some of the ones that are most frequently used in modern deep learning.
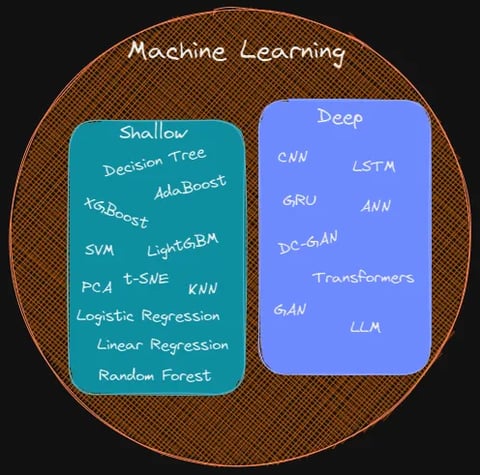
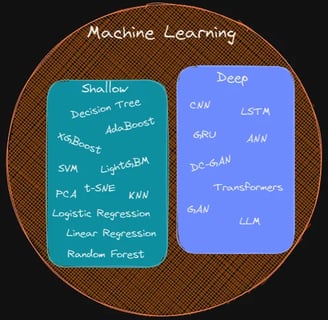
Image Source: Author